Tracking Non Conformant Data (KBA1830)
Applicable Delphix Versions
|
Major Release |
All Sub Releases |
| 5.3 | 5.3.3.0 |
Tracking Nonconforming Data in the Masking Monitor page
Starting version 5.3.3.0, a report on Non Conformant data can be found on the Monitoring Page. This applies to specific algorithms where the data need to match the format or pattern in order to be masked mask. If data does not match the required format - it stays unchanged (which might or might not fail the masking job, depending on the job settings).
When nonconforming data is detected, a warning triangle is set in the Masking Job status UI ( and a report is available via Masking Monitor page.
The warning triangle ( ) is shown on the following pages:
) is shown on the following pages:
- Job Overview Page
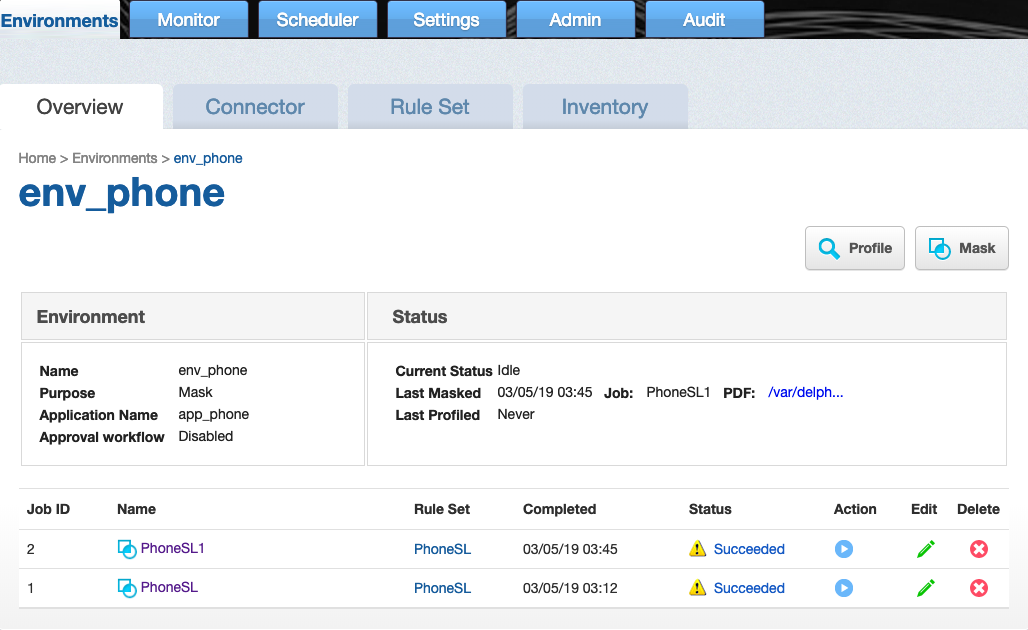
- Job Monitoring Page
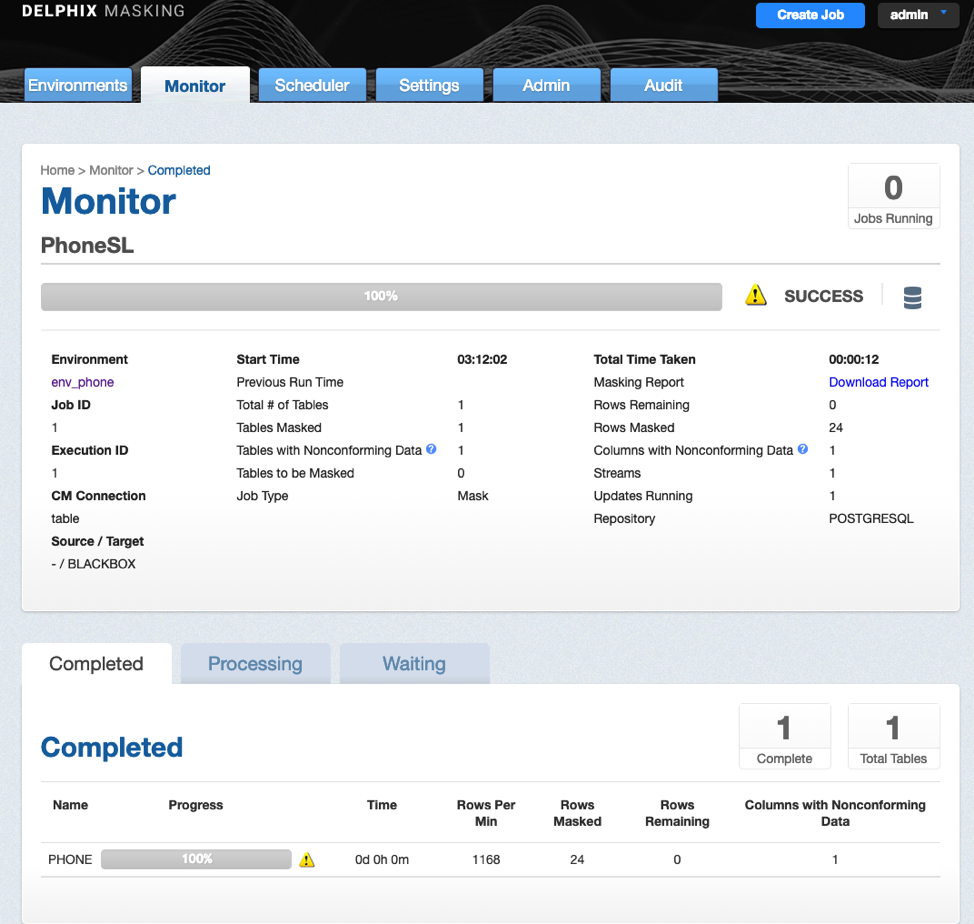
Accessing the Nonconforming Data Report
If Nonconforming data was detected, the report can be accessed using these steps:
- Navigate to the Delphix Masking application.
- Select Monitor tab.
This opens the Monitor page. - Select Tables with Nonconforming Data field.
If value of the field is greater than zero, a (yellow) warning icon is displayed in the Completed section against the row for affected table. - Click on the Warning icon
 in the Completed section.
in the Completed section.
This opens the report providing details.
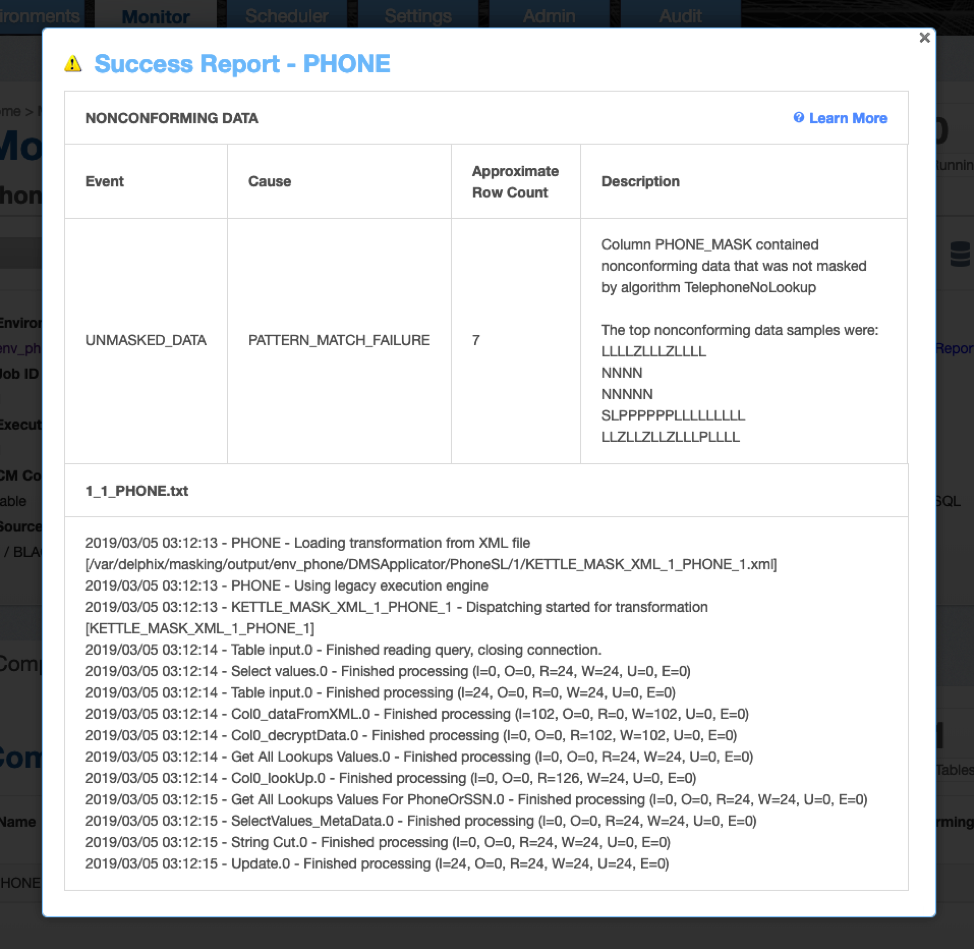
- In the Description for the NONCONFORMING DATA, you might find the top most non conforming data samples (i.e. not all, but first few).
Interpreting the report
Using the example depicted above, the top most nonconforming data samples are:
- LLLLZLLLZLLLL
- NNNN
- NNNNN
- SLPPPPPPLLLLLLLLL
- LLZLLZLLZLLLPLLLL
Each character in the non conforming data is sampled as follows as per Unicode Character Property.
- N for digits
- L for letters
- M for marks
- P for punctuation
- S for symbols
- Z for separator
- O for other
- U for unknown
You can track down the non conforming data using the samples, based on unicode character properties, depending on specific data source type support of regular expressions.
In the above example the data source is Oracle DB. From the report above we can find table name - PHONE, and column name PHONE_MASK.
Below are the Oracle character classes, used in the regular expression:
|
[:alnum:] |
All alphanumeric characters |
|
[:alpha:] |
All alphabetic characters |
|
[:blank:] |
All blank space characters. |
|
[:cntrl:] |
All control characters (nonprinting) |
|
[:digit:] |
All numeric digits |
|
[:graph:] |
All [:punct:], [:upper:], [:lower:], and [:digit:] characters. |
|
[:lower:] |
All lowercase alphabetic characters |
|
[:print:] |
All printable characters |
|
[:punct:] |
All punctuation characters |
|
[:space:] |
All space characters (nonprinting) |
|
[:upper:] |
All uppercase alphabetic characters |
|
[:xdigit:] |
All valid hexadecimal characters |
For the sample in the example above LLLLZLLLZLLLL, the Oracle DB SQL query would look like:
SELECT PHONE_MASK FROM PHONE WHERE regexp_like(PHONE_MASK, '
{4}{3}{4} '); |
This query will return the occurrences of `PHONE_MASK` column in the `PHONE` table, corresponding to the `LLLLZLLLZLLLL` pattern.