How to Generate a Non-Maskable Interrupt NMI in VMware ESX (KBA1129)
Symptoms
There are two typical sets of symptoms when an Engine becomes unresponsive:
1. The Delphix Engine NFS mounts are not responsive, and all target host IO operations fail. The web interface will not load, and attempts to login via SSH are unsuccessful as any Delphix Admin or self-service user, and no login prompt is presented when SSH connection is attempted.
2. The Delphix Engine NFS mounts are responsive, and VDB operations are not disrupted. The web interface will not load, and attempts to login via SSH are unsuccessful as any Delphix Admin or self-service user. A login prompt is received when SSH connection is attempted, but login attempts fail, with no password prompt following the entry of a username.
In both conditions, the hypervisor still indicates the virtual machine (VM) is running, and ping may return successfully. Memory and CPU utilization may be variable, or the VM may indicate no activity.
In condition 1, a non-maskable interrupt (NMI) may be sent from the hypervisor to cause the Delphix operating system (DxOS) to kernel panic and generate a crash dump. The resulting crash dump can be collected by Delphix Support for further analysis.
If there is no response to the NMI on the VM's console, retry the procedure. The final recourse is to reset or power on/off the system which will not generate a core and reduce potential for root cause analysis.
It is important to note that this procedure may not be successful in all cases. Unresponsive VM situations may occur for a variety of reasons related to the guest operating system or ESX hypervisor issues. The following procedure is a best-effort to collect system state information at the time of a VM becoming unresponsive.
In condition 2, a VMware snapshot can be considered instead of, or prior to, an NMI. However, in this condition a Delphix Support user may still be able to login and offer recovery options, so the NMI should not be issued or Engine rebooted until Support is engaged for further direction.
If it is not possible to immediately engage Support, a VM snapshot would be preferred to NMI as this may not be successful in some unresponsive VM conditions.
NMI Procedure, VMware ESXi 6.x, 7.x - vCenter
Although the VMware host client does not offer NMI or other diagnostic facilities through a web interface, if it is available the vCenter web interface can be leveraged to issue NMI to guest.
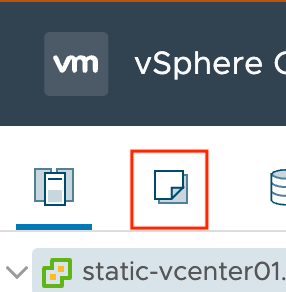
- 1. Login to the vSphere Web Client, and select the desired vCenter from left-hand panel. Click the VMs and Templates tab (2nd icon, highlighted below).
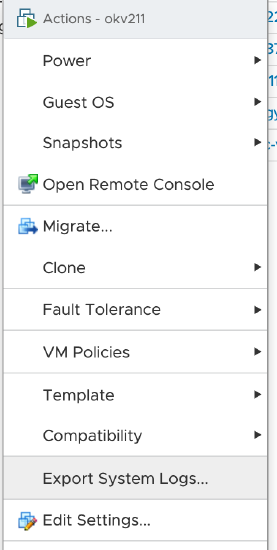
- Locate the Delphix Engine VM in the , and right-click the VM; select Export System Logs...
- In the resulting pop-up interface, expand the HungVM menu option, and click the checkbox Send_NMI_To_Guest.
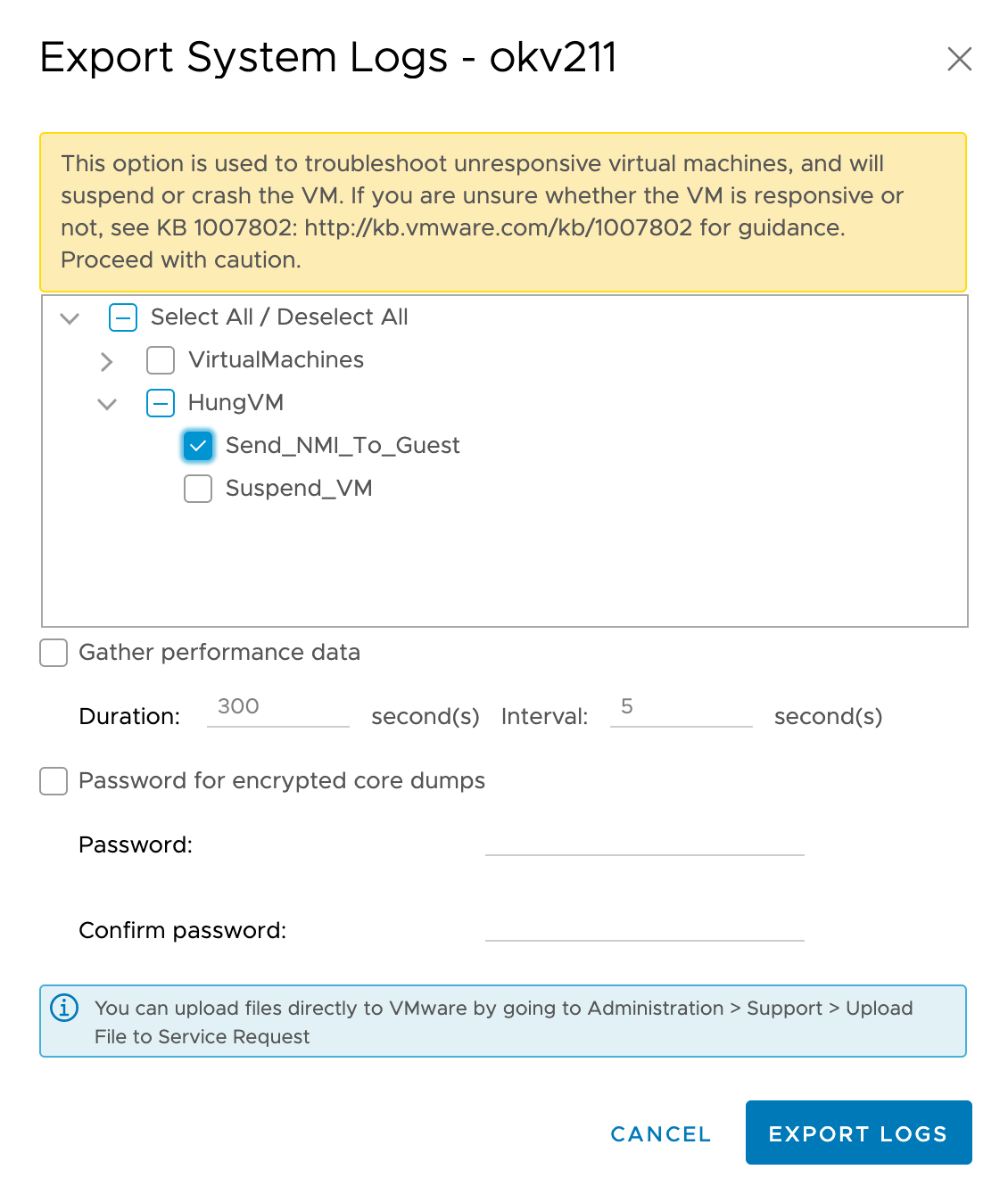
This interface also generates logs which may be provided to Delphix for additional analysis, though the data collected from the VM dump/reboot will be the most critical, along with the Support log bundle.
NMI Procedure, VMware ESX 5.x, 6.x - ESXCLI
- Login to ESX via SSH.
-
At the prompt use the command '
esxcli vm process list'to get the list of VMs and record the World ID. -
Once the World ID is obtained, execute the following command to initiate the NMI: "
vmdumper <world id> nmi". In the example below, the Delphix Engine name is known to be "example5023", which can be used with "grep" to reduce output for parsing.
Example of esxcli and vmdumper commands~ # esxcli vm process list | grep -A 10 example example5023 World ID: 5678754 Process ID: 0 VMX Cartel ID: 5678753 UUID: 56 4d 67 e6 38 d9 70 27-b9 06 56 4c 77 a9 5b 9d Display Name: delphix5023 Config File: /vmfs/volumes/6c25682a-d47ef09e/dlpx-5.0.2.3-55/dlpx-5.0.2.3-55.vmx ~ # vmdumper 5678754 nmi Sending NMI to guest... ~ #
No output beyond "Sending NMI to guest..." is expected. The command prompt should typically return within a few seconds.
-
Other methods are detailed in VMware KB article How to send NMI to Guest OS on ESXi 6.x (2149185).
Advice from VMware
The examples provided above are not intended to provide an exhaustive list of methods to issue NMI. VMware has a number of knowledge base articles of their own relating to diagnosing unresponsive VMs and generating NMIs for those systems. The following articles are especially relevant to the processes discussed above.
Monitoring Delphix VM Console during NMI
During the NMI process, it can be helpful to observe (and record if possible) the Delphix VM console behavior to confirm the NMI is received and to observe the DxOS panic and reboot. Details of the output may vary depending on the Delphix Engine version. When the NMI has completed and the Engine has booted successfully, the desired diagnostic information will need to be retrieved by Delphix Support in a remote session, as this output will not be included in a Support Bundle.
Example Delphix VM console output, versions <6.0
In earlier versions of Delphix (Illumos-based), when NMI is received the following will typically be indicated in the VM console, an indication of a filesystem sync and panic dump being generated before reboot:
panic[cpu0]/thread=ffffff000b805c40: NMI received ffffff000b805aa0 fffffffff791f57f () ffffff000b805ad0 unix:av_dispatch_nmivect+34 () ffffff000b805ae0 unix:nmiint+152 () ffffff000b805bd0 unix:mach_cpu_idle+6 () ffffff000b805c00 unix:cpu_idle+11a () ffffff000b805c20 unix:idle+a7 () ffffff000b805c30 unix:thread_start+8 () syncing file systems... done dumping to /dev/zvol/dsk/rpool/dump, offset 65536, content: kernel 0:03 100% done 100% done: 119831 pages dumped, dump succeeded rebooting...
Example Delphix VM console output, versions >= 6.0
Current versions of Delphix (Linux-based) will immediately log console output indicating a reboot when NMI is received, though the panic dump generation will not be logged to the console in all instances. Delphix Support will be able to determine success of the dump generation attempt, and the collection of this diagnostic data. Please note, the console may log more than one set of restart activity; this is normal.
[ 0.000000] Linux version 5.4.0-65-dx2021051406-63c44010f-generic (root@ip-10-110-205-142) (gcc version 8.4.0 (Ubuntu 8.4.0-1ubuntu1~18.04)) #73~18.04.1 SMP Fri May 14 06:07:38 UTC 2021 (Ubuntu 5.4.0-65.73~18.04.1-generic 5.4.78) [ 0.000000] Command line: BOOT_IMAGE=/ROOT/delphix.QOfkvn5/root@/boot/vmlinuz-5.4.0-65-dx2021051406-63c44010f-generic root=ZFS=rpool/ROOT/delphix.QOfkvn5/root ro console=tty0 console=ttyS0,38400n8 mitigations=off ipv6.disable=1 elevator=noop init_on_alloc=0 usbcore.nousb=1 reset_devices systemd.unit=kdump-tools-dump.service nr_cpus=1 irqpoll nousb ata_piix.prefer_ms_hyperv=0 panic=10 elfcorehdr=9321848K [ 0.000000] KERNEL supported cpus:───────────────────────────────────┘ │ [ 0.000000] Intel GenuineIntel │ [ 0.000000] AMD AuthenticAMD │ [ 0.000000] Hygon HygonGenuine──────────────────────────────────────────┘ [ 0.000000] Centaur CentaurHauls [ 0.000000] zhaoxin Shanghai [ 0.000000] Disabled fast string operations [ 0.000000] x86/fpu: Supporting XSAVE feature 0x001: 'x87 floating point registers' [ 0.000000] x86/fpu: Supporting XSAVE feature 0x002: 'SSE registers' [ 0.000000] x86/fpu: Supporting XSAVE feature 0x004: 'AVX registers' [ 0.000000] x86/fpu: xstate_offset[2]: 576, xstate_sizes[2]: 256 [ 0.000000] x86/fpu: Enabled xstate features 0x7, context size is 832 bytes, using 'standard' format. [ 0.000000] BIOS-provided physical RAM map: [ 0.000000] BIOS-e820: [mem 0x0000000000001000-0x000000000009ebff] usable [ 0.000000] BIOS-e820: [mem 0x00000000af000000-0x00000000beffffff] usable [ 0.000000] BIOS-e820: [mem 0x00000000bfed0000-0x00000000bfefefff] ACPI data [ 0.000000] BIOS-e820: [mem 0x00000000bfeff000-0x00000000bfefffff] ACPI NVS [ 0.000000] BIOS-e820: [mem 0x0000000229000000-0x0000000238f5dfff] usable [ 0.000000] BIOS-e820: [mem 0x0000000238fffc00-0x0000000238ffffff] usable [ 0.000000] NX (Execute Disable) protection: active [ 0.000000] SMBIOS 2.4 present. [ 0.000000] DMI: VMware, Inc. VMware Virtual Platform/440BX Desktop Reference Platform, BIOS 6.00 12/12/2018
If any issue is encountered during the DxOS panic dump, the process may take up to 2 hours to time out. If the "NMI received" activity is NOT observed in the console, the Engine may still be rebooted but this indicates diagnostic information may not be generated as the NMI was not registered by the Engine. If you are receiving messages on the console and it stops responding for a long period of time (>30m), particularly at any point during syncing file systems or incrementing the amount of pages dumped, it is likely that it will not complete. You can observe the VM from the hypervisor to try to make a determination of whether there is enough activity to warrant giving it additional time or proceed with resetting the VM.
VMware Snapshot
VMware provides instructions on generating a VM snapshot in the following knowledge document:
https://kb.vmware.com/s/article/1015180
During this operation, it is imperative that the "Snapshot the virtual machine's memory" option is selected, to capture the live VM memory state, as the VM hang condition may prevent the ability to write diagnostic information to the Engine filesystems, and therefore prevent root cause analysis from being completed.