Linking SQL Server Always On Availability Groups (KBA1603)
KBA
KBA#1603
What are SQL Server Always On Availability Groups?
An Always On Availability Group (also referred to as AlwaysOn, Availability Groups, AOAG or AG) creates a failover environment for a set of databases. This set of databases is constantly synced across a discrete set of replicas, which are basically instances sitting on separate physical hosts. Of these two to five replicas, one is the primary, and it accepts read/write requests. The other secondary replicas can optionally be configured to provide read-only access. This is one significant advantage over normal failover clustering, since secondary machines can now have their storage leveraged. An Availability Group also syncs its replicas without shared storage, another significant advantage of this configuration. Replica instances are in constant communication with one another to stay up to date.
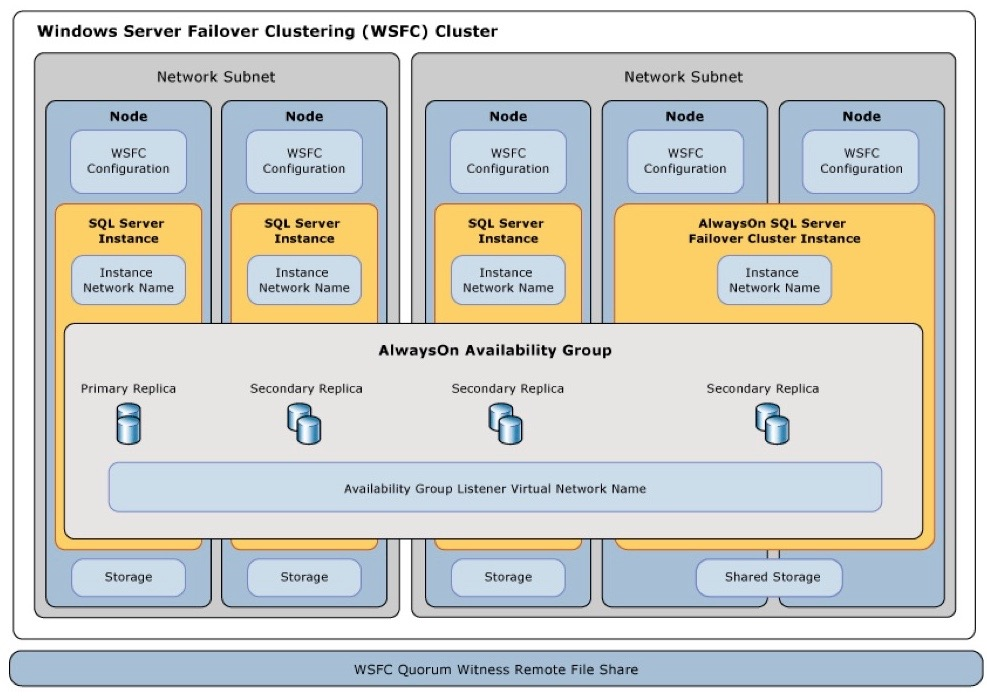
Availability Group Configuration
Microsoft's diagram in their document Windows Server Failover Clustering with SQL Server provides a helpful visual for Availability Group Configuration:
Discovery
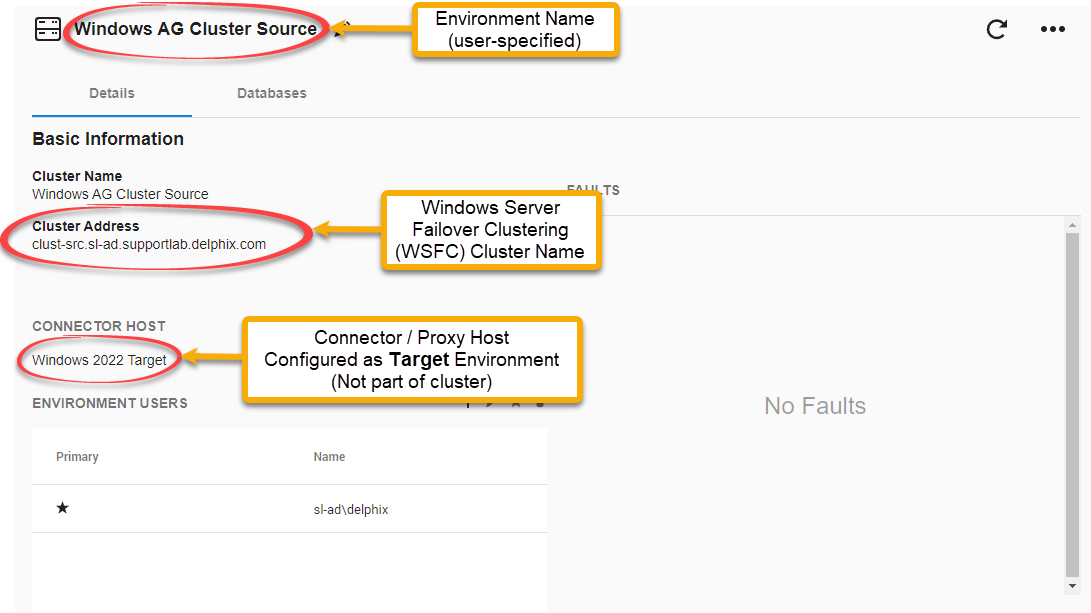
After discovery, viewing the cluster from the Environments screen will show all Availability Groups that the Continuous Data Engine has discovered.
The Details tab show basic Information about the Windows Cluster, including the Windows Server Failover Clustering cluster name, and the Connector Host that is used to perform Environment monitoring and Environment Refresh operations:
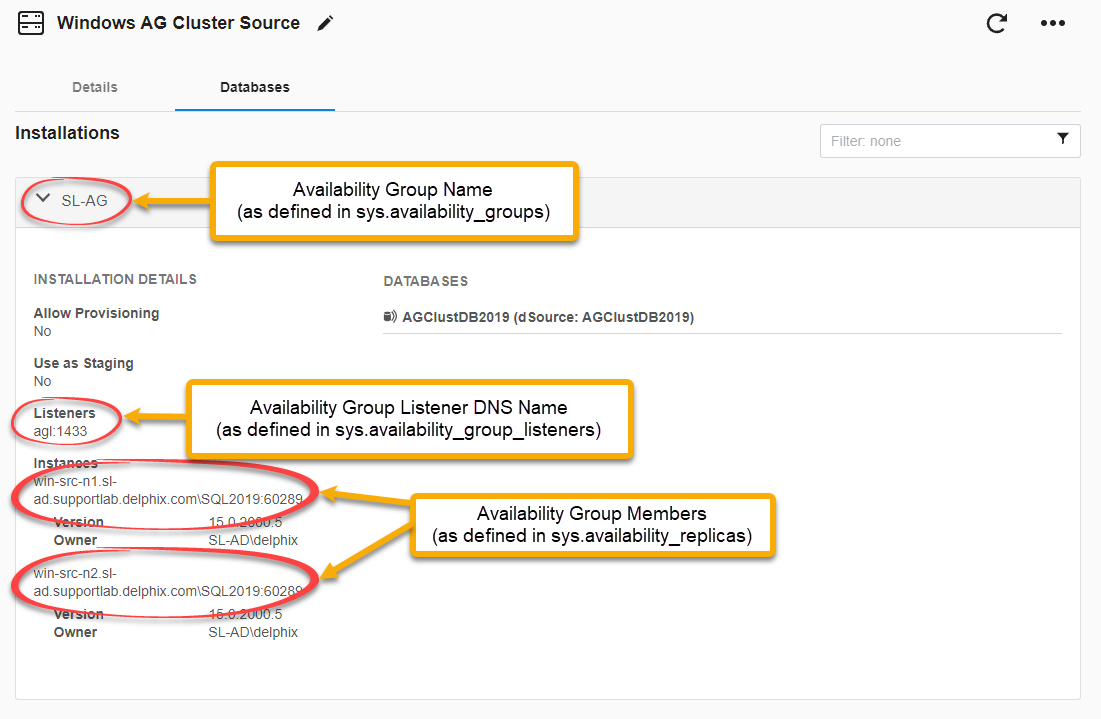
The Databases tab will show details of each Availability Group that has been discovered on that cluster:
Discovery of Availability Group Source Environments uses the following process:
- Connect to the configured Cluster Address using Windows Remote Registry features.
- Using the Registry, list all nodes that participate in the Windows Cluster.
- Connect to each node using Windows Remote Registry features and discover the SQL Server instances on each node.
- For each discovered SQL Server instance:
- Connect to the SQL Server instance using the SQL Server
sqlcmdutility. - Validate that the instance is configured for Availability Groups.
- Discover the Availability Groups and Availability Group Databases present on the instance.
- Update the Continuous Data Engine with the results of discovery.
Linking
Databases that are part of an Availability Group can be linked through the Availability Group Listener, using the process described in Linking a dSource from a SQL server: An overview.
During dSource operations, the Staging Host will check all configured Backup Path(s) regardless of the node which performed the backup. If Availability Group Nodes are taking backups to local storage, multiple Backup Paths will need to be added as part of the dSource configuration.
Validated Sync
The Validated Sync for Availability Groups - where the Continuous Data Engine monitors for new backups and takes dSource Snapshots - requires querying all of the nodes in the group. Because backup strategies for Availability Groups can vary greatly, Delphix cannot anticipate where the next backup will be taken. Only the node which took the backup has the information about where to find the backup files.
To accommodate this, the Continuous Data Engine queries all of the nodes for a list of backups that were taken since the latest restored backup. Then, it compares these backups to figure out which one is the earliest.
We can detect if a backup is missing by comparing the LSNs of the next backup to be restored and the latest restored backup. Availability Groups do not allow backups to be taken in simple mode, so log chain break is impossible. If there is a gap between the last LSN of the latest restored backup and the first LSN of the next backup to be restored, a backup is missing and a Fault will be raised.
Adding an Availability Group as a Source Environment
To add an Availability Group as a Source Environment:
- Ensure that a Target Environment has been configured that can be used as a Connector Host. The Continuous Data Engine will use this server to interact with the Windows cluster and its nodes.
- Ensure that the nodes of the Source Environment meet the requirements described in Overview of requirements for SQL Server environments.
- Ensure that any Availability Groups to be discovered are configured with an Availability Group Listener.
- Follow the instructions in the document Adding a SQL Server source environment.
- Add the environment with Host Type Source, Server Type Cluster.
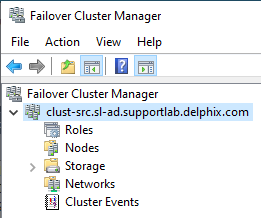
- When entering the Cluster Address, use the hostname of the Windows Server Failover Cluster, or the hostname of any cluster node. The Continuous Data Engine will discover Availability Groups, and any Availability Group Virtual Hostnames should not be used for discovery.
The Cluster Address is visible from the Windows Failover Cluster Manager utility, when run from any cluster node:
Always On Availability Group Restrictions
The following requirements, limitations and restrictions exist when working with Always On Availability Groups and the Continuous Data Engine:
- It is not possible to provision VDBs into Availability Groups at this time.
- An Availability Group Listener is required for each Availability Group be discovered, because the engine connects to this listener to discover the active cluster nodes when monitoring a dSource during Validated Sync. This requirement is described in Overview of requirements for SQL Server environments.
- Hostnames of all servers must resolve to Fully Qualified Domain Names (FQDN) when queried via DNS.
- Additional configuration may be required for Always On Availability Groups that are deployed in cloud environments such as Azure and AWS. This is described in our document Additional requirements for azure SQL server availability groups.
- The Continuous Data Engine will not currently discover Windows Server Failover Cluster Environments that have been configured to use Distributed Network Names (DNN) for the Cluster Core Resource. Clusters must be configured with a Virtual Network Name (VNN).