Algorithm: Data Cleansing (KBA1662)
KBA
KBA# 1662At a Glance
| Description: | This algorithm is used to Cleanse Data (or standardize in Data Quality terms). Even if rare, it can be used to obfuscate the data. The algorithm uses lookup values to change a set of terms to another (standard) set of terms. This algorithm is lightweight and fast. The KBA is for Data Cleanse v1. |
||||||||
|---|---|---|---|---|---|---|---|---|---|
| New Version: | The Data Cleanse algorithm has been updated and the latest release is available from Delphix Continuous Compliance Engine version 6.0.14.0. | ||||||||
| Characteristics: |
1 Referential Integrity - The cleaned value will be the same between job executions as well as tables. |
||||||||
| Character Encoding: |
Uses UTF-8 (some limitations if the code page is not supported - DLPX-43116). | ||||||||
| Lookup Pool: | For best performance - up to 500,000 values. | ||||||||
| Notes: | Notes:
|
||||||||
| Create/Modify: | Creation: Lookup values are loaded when the algorithm is created from a text file. Modify: The description and the list of lookup values can be changed. |
||||||||
| More info: | Data Cleanse v2 documentation:
|
Overview
The Data Cleansing Algorithm is a simple algorithm that uses a lookup file with mappings of original/cleansed value pairs. These value pairs are imported when you create or modify the Data Cleansing algorithm.
This algorithm has been upgraded to the New Algorithm Framework as of Delphix Continuous Compliance Engine version 6.0.14.0.
Applicable Delphix Versions
- Click here to view the versions of the Delphix engine to which this article applies
-
Major Release All Sub Releases 6.0 6.0.0.0, 6.0.1.0, 6.0.1.1, 6.0.2.0, 6.0.2.1, 6.0.3.0, 6.0.3.1, 6.0.4.0, 6.0.4.1, 6.0.4.2, 6.0.5.0, 6.0.6.0, 6.0.6.1, 6.0.7.0, 6.0.8.0, 6.0.8.1, 6.0.9.0, 6.0.10.0, 6.0.10.1, 6.0.11.0, 6.0.12.0, 6.0.12.1, 6.0.13.0, 6.0.13.1, 6.0.14.0, 6.0.15.0, 6.0.16.0, 6.0.17.0, 6.0.17.2
5.3
5.3.0.0, 5.3.0.1, 5.3.0.2, 5.3.0.3, 5.3.1.0, 5.3.1.1, 5.3.1.2, 5.3.2.0, 5.3.3.0, 5.3.3.1, 5.3.4.0, 5.3.5.0, 5.3.6.0, 5.3.7.0, 5.3.7.1, 5.3.8.0, 5.3.8.1, 5.3.9.0 5.2
5.2.2.0, 5.2.2.1, 5.2.3.0, 5.2.4.0, 5.2.5.0, 5.2.5.1, 5.2.6.0, 5.2.6.1
5.1
5.1.0.0, 5.1.1.0, 5.1.2.0, 5.1.3.0, 5.1.4.0, 5.1.5.0, 5.1.5.1, 5.1.6.0, 5.1.7.0, 5.1.8.0, 5.1.8.1, 5.1.9.0, 5.1.10.0
5.0
5.0.1.0, 5.0.1.1, 5.0.2.0, 5.0.2.1, 5.0.2.2, 5.0.2.3, 5.0.3.0, 5.0.3.1, 5.0.4.0, 5.0.4.1, 5.0.5.0, 5.0.5.1, 5.0.5.2, 5.0.5.3, 5.0.5.4
Creating and Modifying
The algorithms are accessed from the tab Settings and under the submenu Algorithm. Once created, the algorithm can be modified:
- To create click Add Algorithm at the top of the page.
- To modify click the Edit icon next to each algorithm.
User Interface
When creating (and modifying) the algorithm, the following popup will display:
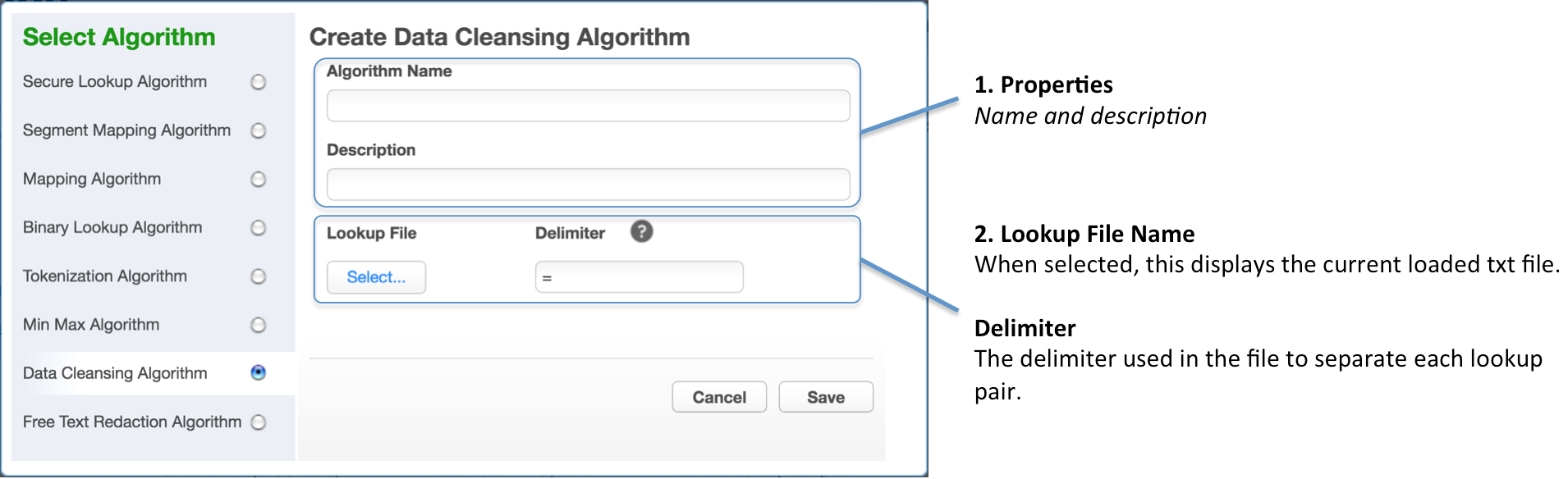
- Algorithm Properties:
- Algorithm Name.
- Description.
- Lookup Details:
- Lookup File Name.
- Delimiter - the character used in the file to separate mappings of original/cleansed value pairs.
Modification
Editable parameters are:
- Description
- List of lookup values
Considerations
Pool Size and Performance
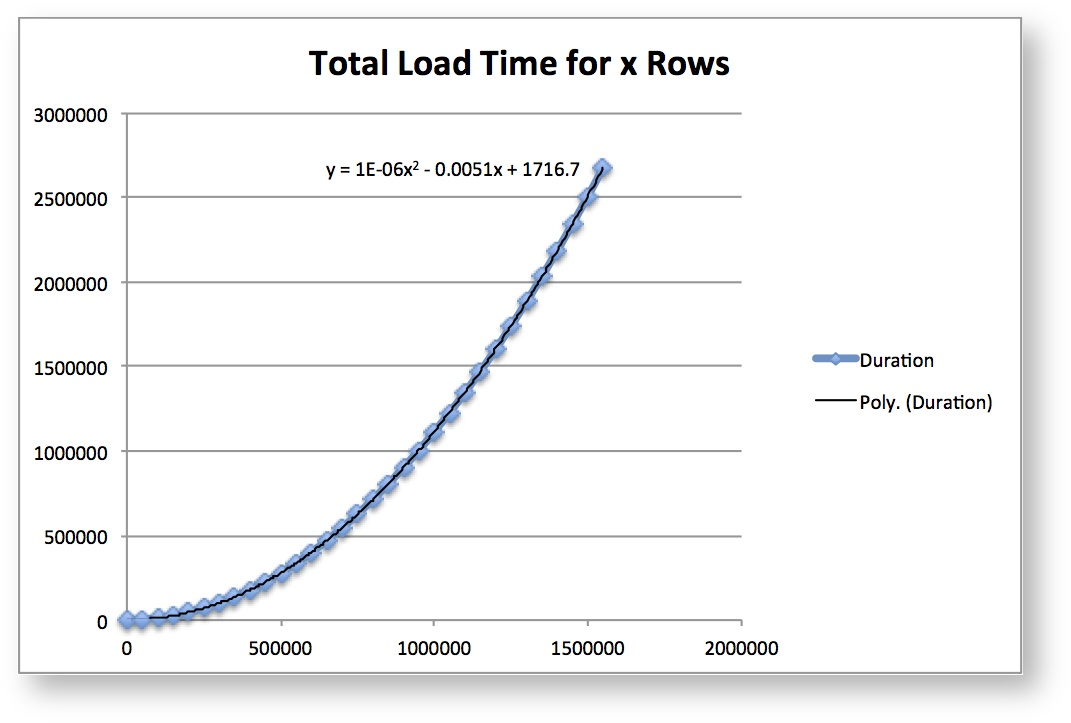
The pool size (number of rows in the lookup file) affects both the algorithm creation time and the load time when the job starts up. An estimate is that the increase in load time is 10 to 3 - increase the number of values by 3 times and it will take 10 times longer to load. On an average system, it will take 4 min to load 500,000 values. Loading 1,500,00 will take 40 min.
The graph below shows the load values in milliseconds (y) and in the number of values loaded on the horizontal axis (x).
Memory Requirements
The ingested values are loaded into RAM when the masking job starts. For large pool sizes, it might be required to increase the Min/Max Memory settings in the Job Configuration.
White Space Workaround
The Data Cleansing Algorithm is sensitive to white spaces and case. This can be a problem if the data being masking is stored in a CHAR (or NCHAR) column as these values will be padded.
To resolve white space issues on a database, use this workaround:
- Open and edit the Rule Set
- Add a Custom SQL statement with the following amendment to the column that needs to be trimmed:
From : maskCol
To : LTRIM(RTRIM((maskCol)) as maskCol
Example:
SELECT ID, LTRIM(RTRIM((maskCol)) as maskCol from myTable;
Case Sensitivity Workaround
To resolve case sensitivity on a database, use this workaround:
- Open and edit the Rule Set
- Add a Custom SQL statement with the following amendment to the column with the case issue:
From : maskCol
To : UPPER((maskCol)) as maskCol
Example:
SELECT ID, UPPER(maskCol) as maskCol from myTable;
Non-Standard Code Page
The data to be masked might be encoded and contain characters that are not converted correctly to UTF-8. The masked data is masked as????. This issue is resolved in version 5.1.
Examples
Below is an example of cleansed results using varchar. Note the case and white space sensitivity.
Text file with search lookup values:
tst=test Tst=Test TST=TEST
Masking (cleansed) result:
+-----+--------+----------+ | ID | Orig | Cleansed | +-----+--------+----------+ | 1 | tst | test | | 2 | Tst | Test | | 3 | TST | TEST | +-----+--------+----------+ | 4 | tsT | tsT | << Not cleansed >> no search value match | 5 | TST | TST | << Not cleansed >> trailing white space +-----+--------+----------+