Masking Method: On-The-Fly and In-Place (KBA1774)
KBA
KBA#1774This KBA details how to create In-Place (IP) and On-The-Fly (OTF) masking jobs. The page mostly uses the terms Database and Masking but the details apply to Files and Tokenization, as well.
Applicable Delphix Versions
- Click here to view the versions of the Delphix engine to which this article applies
-
Major Release All Sub Releases 6.0 6.0.0.0, 6.0.1.0, 6.0.1.1, 6.0.2.0, 6.0.2.1, 6.0.3.0, 6.0.3.1, 6.0.4.0, 6.0.4.1, 6.0.4.2, 6.0.5.0, 6.0.6.0, 6.0.6.1, 6.0.7.0, 6.0.8.0, 6.0.8.1, 6.0.9.0, 6.0.10.0, 6.0.10.1, 6.0.11.0, 6.0.12.0, 6.0.12.1 5.3
5.3.0.0, 5.3.0.1, 5.3.0.2, 5.3.0.3, 5.3.1.0, 5.3.1.1, 5.3.1.2, 5.3.2.0, 5.3.3.0, 5.3.3.1, 5.3.4.0, 5.3.5.0, 5.3.6.0, 5.3.7.0, 5.3.7.1, 5.3.8.0, 5.3.8.1, 5.3.9.0 5.2
5.2.2.0, 5.2.2.1, 5.2.3.0, 5.2.4.0, 5.2.5.0, 5.2.5.1, 5.2.6.0, 5.2.6.1
5.1
5.1.0.0, 5.1.1.0, 5.1.2.0, 5.1.3.0, 5.1.4.0, 5.1.5.0, 5.1.5.1, 5.1.6.0, 5.1.7.0, 5.1.8.0, 5.1.8.1, 5.1.9.0, 5.1.10.0
5.0
5.0.1.0, 5.0.1.1, 5.0.2.0, 5.0.2.1, 5.0.2.2, 5.0.2.3, 5.0.3.0, 5.0.3.1, 5.0.4.0, 5.0.4.1, 5.0.5.0, 5.0.5.1, 5.0.5.2, 5.0.5.3, 5.0.5.4
At a Glance
| Description: | This article describes the two masking methods:
|
||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Use Cases: | The most common use cases (Best Practice) for each method are:
|
||||||||||||||||
| Database: |
1 Unique Row Identifier - The unique Update Key (can be one or multiple columns). |
||||||||||||||||
| File: |
|
||||||||||||||||
| Masked vDB: | Masked vDBs are only available on IP Database masking. | ||||||||||||||||
| Performance: | For database masking - IP and OTF:
|
||||||||||||||||
| Read more: | Other useful sources: |
In-Place
When using the In-Place method, the data is read from the Target, masked, and then Updated back to the Target.
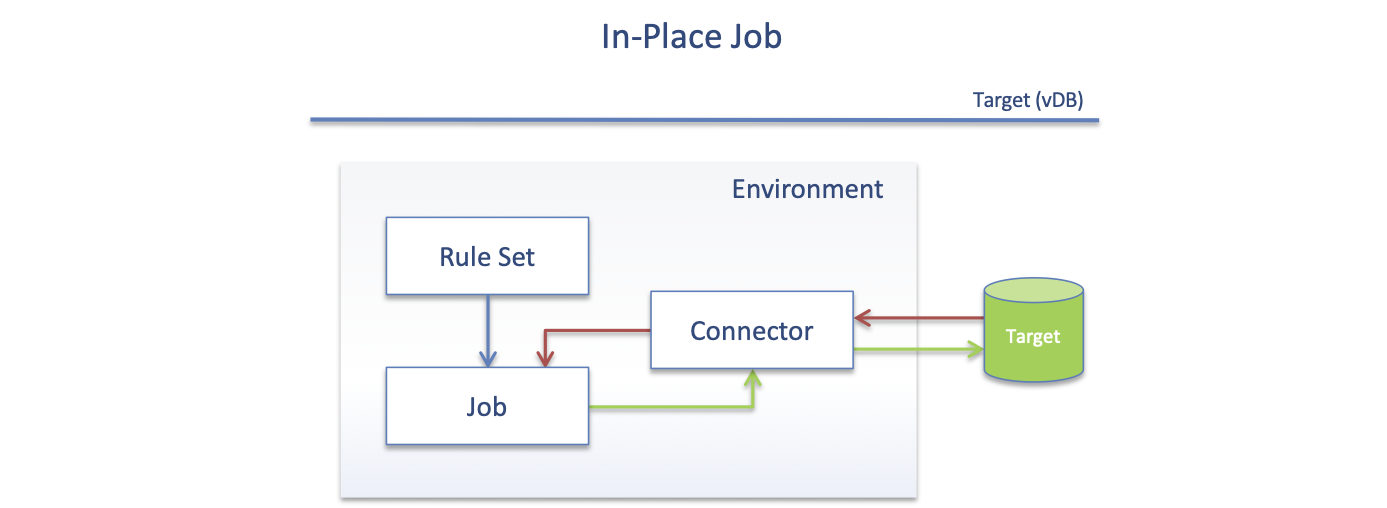
How to create
- Create a VDB or a copy of the Database to be masked. This will be the target.
- Create an Environment (for example called Target). View the environment.
- Create a Connector (for example called Target_CON).
- Create a Rule Set.
- Open the Inventory and define Masked Columns, alternatively use Profiling.
- Click Overview and create a Masking Job.
Create using API
The job created above looks like this using the API.
- Environment: Target
- Connector: Target_Con
- Rule Set: MY_RS
- Job: IP_MASK
| 1. Environments | 3. Rule Set |
| [ { "environmentId": 1, "environmentName": "Target", "application": "App", "purpose": "MASK", "isWorkflowEnabled": false } ] |
[ { "databaseRulesetId": 1, "rulesetName": "MY_RS", "databaseConnectorId": 1, "refreshDropsTables": false } ] |
| 2. Connectors | 4. Job |
| [ { "databaseConnectorId": 1, "connectorName": "Target_CON", "databaseType": "MSSQL", "environmentId": 1, "databaseName": "Target", "host": "10.43.97.248", "instanceName": "SQL2016", "port": 1433, "schemaName": "dbo", "username": "sa", "kerberosAuth": false } ] |
[ { "maskingJobId": 1, "jobName": "IP_MASK", "rulesetId": 1, "feedbackSize": 50000, "jobDescription": "", "maxMemory": 1024, "minMemory": 1024, "multiTenant": false, "numInputStreams": 1, "onTheFlyMasking": false, "databaseMaskingOptions": { "batchUpdate": true, "bulkData": false, "commitSize": 10000, "disableConstraints": false, "dropIndexes": false, "disableTriggers": false, "numOutputThreadsPerStream": 1, "truncateTables": false }, "failImmediately": false } ] |
On-The-Fly
The one main rule when configuring On-The-Fly masking is that the Source can Never be masked. The On-The-Fly Rule Set and Job are, therefore, defined against the Target.
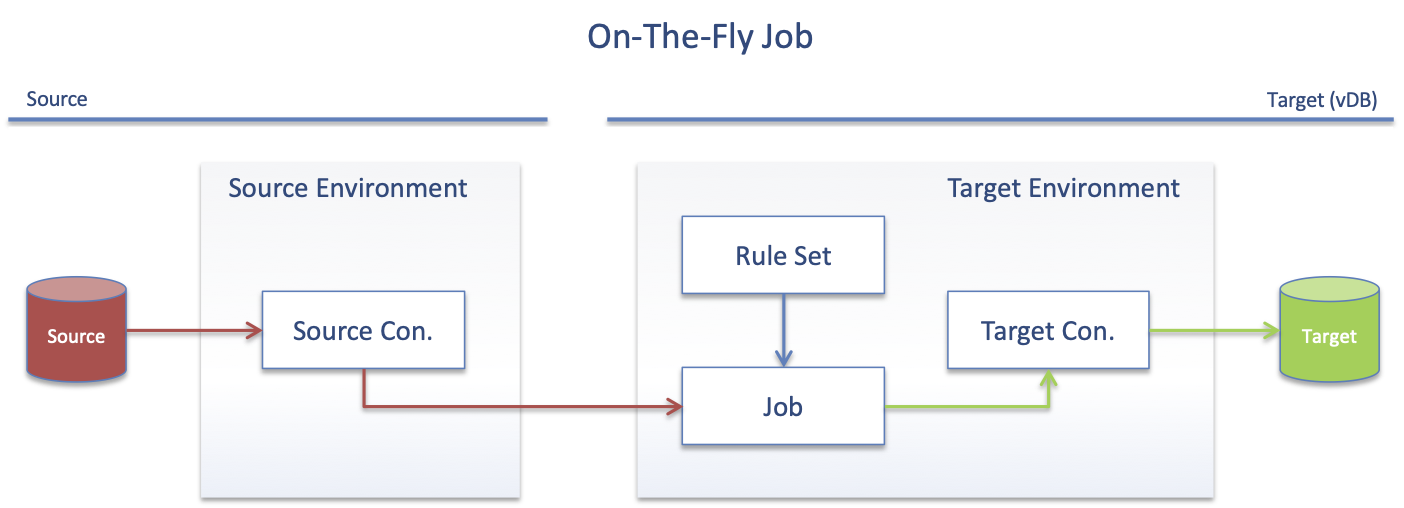
Configuration
| Requirements | Source | Target |
Masked Object:
|
Object:
|
Object:
|
Masking Engine:
|
Objects:
|
Objects:
|
How to create
To mask the Target:
It is recommended to start with the target.
- Create a copy of the Database to be masked
This will be the target. - Create an Environment (for example called Target).
View the environment. - Create a Connector to the Target (for example called Target_CON).
- Create a Rule Set.
- Open the Inventory and define Masked Columns, alt use Profiling.
To mask the Source:
- Create an Environment (for example called Source).
View the environment. - Create a Connector to the Source (for example called Source_CON).
To create the masking job:
- Navigate to the Target Environment.
- Click Overview and create a Masking Job.
It is recommended to use a VDB as the source.
Create using API
The job created above looks like this using the API.
- Environment: Target
- Connector: Target_Con
- Rule Set: MY_RS
- Job: IP_MASK
- Environment: Source
- Connector: Source_CON
| 1. Environments | 3. Rule Set |
| [ { "environmentId": 1, "environmentName": "Target", "application": "App", "purpose": "MASK", "isWorkflowEnabled": false }, { "environmentId": 2, "environmentName": "Source", "application": "App", "purpose": "MASK", "isWorkflowEnabled": false } ] |
[ { "databaseRulesetId": 1, "rulesetName": "MY_RS", "databaseConnectorId": 1, "refreshDropsTables": false } ] |
| 2. Connectors | 4. Job |
| [ { "databaseConnectorId": 1, "connectorName": "Target_CON", "databaseType": "MSSQL", "environmentId": 1, "databaseName": "Target", "host": "[Target Host]", "instanceName": "SQL2016", "port": 1433, "schemaName": "dbo", "username": "sa", "kerberosAuth": false }, { "databaseConnectorId": 2, "connectorName": "Source_CON", "databaseType": "MSSQL", "environmentId": 2, "databaseName": "Source", "host": "[Source Host]", "instanceName": "SQL2016", "port": 1433, "schemaName": "dbo", "username": "sa", "kerberosAuth": false } ] |
[ { "maskingJobId": 1, "jobName": "OTF_MASK", "rulesetId": 1, "feedbackSize": 50000, "jobDescription": "", "maxMemory": 1024, "minMemory": 1024, "multiTenant": false, "numInputStreams": 1, "onTheFlyMasking": true, "databaseMaskingOptions": { "batchUpdate": true, "bulkData": false, "commitSize": 10000, "disableConstraints": false, "dropIndexes": false, "disableTriggers": false, "numOutputThreadsPerStream": 1, "truncateTables": false }, "onTheFlyMaskingSource": { "connectorId": 2, "connectorType": "DATABASE" }, "failImmediately": false } ] |
More Information
In-Place
- Requires a Unique Row Identifier (URI) - Update Key, usually the Primary Key (PK), to mask the data.
- Uses UPDATE SQL Statement to change masked data.
- Only the URI and the masked data are needed in the masking job (unless explicitly detailed in the Custom SQL or Algorithm).
- Transfers less data but can have problems masking indexes.
- The URI CANNOT be masked. Therefore:
- Masking jobs will pick PK or IDENTITY column as the URI - Update Key.
- If a URI does not exist - a URI has to be created manually (on some databases this process is automatic).
- Oracle uses ROWID.
DB2 has a similar column as Oracle but this is configurable so check with the DBA.
On-The-Fly
- Reads the 'Source' Database.
- Does not require a Unique Row Identifier (URI).
- Uses INSERT SQL statement to insert data into the Target.
- The Source, Target schema needs to match and match with the Rule Set (see OTF Error below).
- As the masked data is inserted, the tables need to be empty:
- run the job with Truncate.
- Or manually delete (or create fresh Target).
- All data from each row is read so this method transfers more data.
- Large fields can slow down the job significantly (on Database Cast can be used to reduce the size).
- Large fields can slow down the job significantly (on Database Cast can be used to reduce the size).
Requirements
Both Masking Methods require the following on any Masked columns:
- Constraints to be disabled (or dropped).
- Primary Keys (PK) to be dropped.
Note:
The constraint issue (also on PK) means that the masked data needs to be Unique and for In-Place the masked value CANNOT already be in the column, or the update will violate the Constraint.
If the masked data is not unique, the Constraint and the PK cannot be re-established.
Performance Notes
For best Database performance:
- IP and OTF:
- Disable triggers.
- Drop indexes on masked columns.
- OTF:
- Large fields requires a lot of bandwidth - use Cast to reduce the size.
Troubleshooting
OTF Error: Rule Set not matching Source/Target
- Method: OTF
- Version: 5.3.6.0
- Cause: This error is cryptic. The Source schema and the Rule Set are not matching. This generates the NullPointerException.
- Resolution:
- Ensure that the schema (table and columns) match the Source and Target.
- Refresh the Rule Set.
[JOB_ID_xx_yy] ERROR 17-09 21:35:03,956 - Table input - You need to specify a database connection. [JOB_ID_xx_yy] ERROR 17-09 21:35:03,956 - Table input - Error initializing step [Table input] [JOB_ID_xx_yy] ERROR 17-09 21:35:03,957 - TableOutput - Error initializing step [TableOutput] [JOB_ID_xx_yy] ERROR 17-09 21:35:03,958 - TableOutput - java.lang.NullPointerException [JOB_ID_xx_yy] at org.pentaho.di.trans.steps.tableoutput.TableOutput.init(TableOutput.java:559) [JOB_ID_xx_yy] at org.pentaho.di.trans.step.StepInitThread.run(StepInitThread.java:62) [JOB_ID_xx_yy] at java.lang.Thread.run(Thread.java:748)
Related Articles
Knowledge Base Links:
- Masking Performance for Database (KBA1561)
- Best Practice: Job Configuration Settings (KBA1048)
- Best Practice: File Masking Job Configuration (KBA1821)