Algorithm: Mapping Algorithm (MA) (KBA1328)
KBA
KBA#1328This algorithm is called MA for short. There are no MA algorithms shipped out of the box with the Masking Engine. An MA algorithm needs to be created.
Use this algorithm when there cannot be any duplicate values and the masked data need to be 1:1 with the original. The MA algorithm has a pool of unmapped lookup values, which can be topped up when needed.
Applicable Delphix Versions
- Click here to view the versions of the Delphix engine to which this article applies
-
Major Release All Sub Releases 6.0 6.0.0.0, 6.0.1.0, 6.0.1.1, 6.0.2.0, 6.0.2.1, 6.0.3.0, 6.0.3.1, 6.0.4.0, 6.0.4.1, 6.0.5.0, 6.0.6.0, 6.0.6.1, 6.0.7.0, 6.0.8.0, 6.0.8.1 5.3
5.3.0.0, 5.3.0.1, 5.3.0.2, 5.3.0.3, 5.3.1.0, 5.3.1.1, 5.3.1.2, 5.3.2.0, 5.3.3.0, 5.3.3.1, 5.3.4.0, 5.3.5.0 5.3.6.0, 5.3.7.0, 5.3.7.1, 5.3.8.0, 5.3.8.1, 5.3.9.0 5.2
5.2.2.0, 5.2.2.1, 5.2.3.0, 5.2.4.0, 5.2.5.0, 5.2.5.1, 5.2.6.0, 5.2.6.1
5.1
5.1.0.0, 5.1.1.0, 5.1.2.0, 5.1.3.0, 5.1.4.0, 5.1.5.0, 5.1.5.1, 5.1.6.0, 5.1.7.0, 5.1.8.0, 5.1.8.1, 5.1.9.0, 5.1.10.0
5.0
5.0.1.0, 5.0.1.1, 5.0.2.0, 5.0.2.1, 5.0.2.2, 5.0.2.3, 5.0.3.0, 5.0.3.1, 5.0.4.0, 5.0.4.1 ,5.0.5.0, 5.0.5.1, 5.0.5.2, 5.0.5.3, 5.0.5.4
4.3
4.3.1.0, 4.3.2.0, 4.3.2.1, 4.3.3.0, 4.3.4.0, 4.3.4.1, 4.3.5.0
4.2
4.2.0.0, 4.2.0.3, 4.2.1.0, 4.2.1.1, 4.2.2.0, 4.2.2.1, 4.2.3.0, 4.2.4.0 , 4.2.5.0, 4.2.5.1
4.1
4.1.0.0, 4.1.2.0, 4.1.3.0, 4.1.3.1, 4.1.3.2, 4.1.4.0, 4.1.5.0, 4.1.6.0
At a Glance
| Description: | This is a commonly used algorithm very similar to Secure Lookup with the difference that this generates a guaranteed 1:1 mapping. The lookup data is stored in the internal masking repository (database). The content in the MA needs to be imported and the mapping 'stays' with the algorithm until recreated (5.3). |
||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Characteristics: |
1 Unique Lookup - Lookup values are all unique within the algorithm (dedup of new data each load time). New data can be loaded (need to be new (not loaded before) or it will not be added to the pool). |
||||||||||||
| Character Encodings: |
Works with all characters encodings (some bugs are known). See below for the workaround. |
||||||||||||
| Lookup Pool Size: | The size of the lookup pool depends on the amount of memory. For performance and memory, the recommended size is up to around 5,000,000.
Note: there are two processes to consider: If a very large number of values are needed to be uniquely masked it would be better to use Segmented Mapping or Tokenization. |
||||||||||||
| Notes: | Notes and observations:
|
||||||||||||
| Duplicates: | From version 5.3, there are multiple dedup processes and duplicates are not likely. In older versions, a common root cause for duplicates was that the same value was imported twice.
If the algorithm has duplicates (see note below) the algorithm has to be re-created. |
||||||||||||
| Version Updates: | In version 5.2 the load time was improved. In version 5.3 the dedup was improved. KBA updated using 6.0.9. |
Creating and Modifying Algorithms Using the User Interface
The algorithms are accessed from the Settings tab and under the submenu Algorithm. From the Algorithm page, an MA algorithm can be created and also modified (edit):
- To create, click "Add Algorithm".
- To modify, click the green pen in the "Edit" column.
User Interface
The following popup screens are accessed when creating and modifying the algorithm:
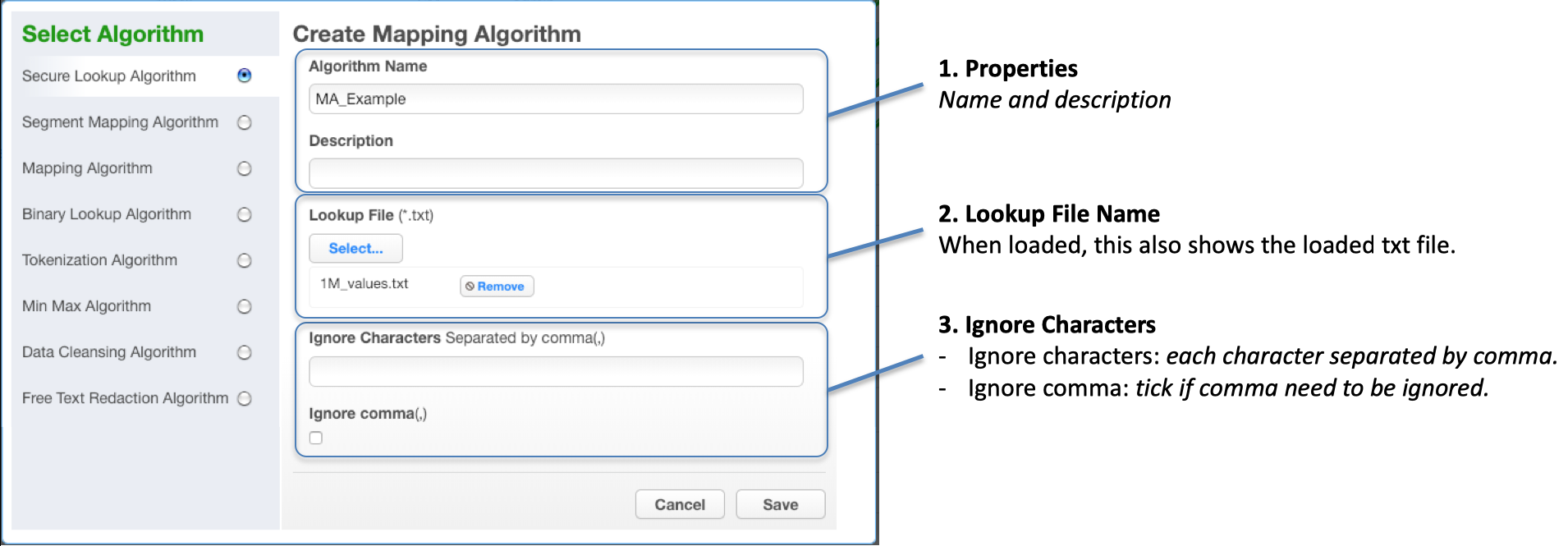
- When creating an algorithm, lookup values are loaded when the algorithm is created from a text file. You need to provide details for Algorithm Properties:
- Algorithm Name
- Description
- When modifying an algorithm, the Lookup details (description and lookup value) can be modified:
- Lookup File Name
- Delimiter - the character used in the file to separate search and lookup value
The following popup is presented when modifying the Mapping algorithm.

The editable parameters are:
- Description
- Append Lookup File
- The list of lookup values can be appended to the existing list or replacing the existing list.
- Note that for versions prior to 5.3. you need to select Append if necessary, else mappings will change.
- Ignore Characters
Considerations
Since the algorithm is retaining all mappings, new mappings are taken from a lookup pool. Therefore, the pool of lookup values needs to be larger than the distinct set of new values to mask.
Recommendation
Version 5.3 has some key improvements in the preparation process. We recommend the use of 5.3 or later versions.
Mapping Values - Load and Map Processes
The diagram below shows how the Mapping Algorithm uses three storage containers in the masking engine. These are used in two different processes:
- Load Values - when the algorithm is Created or Edited.
- Map Values - where new data to be masked is mapped to available mapping values.
Load and Map Values are trimmed (whitespaces removed) in the import process.
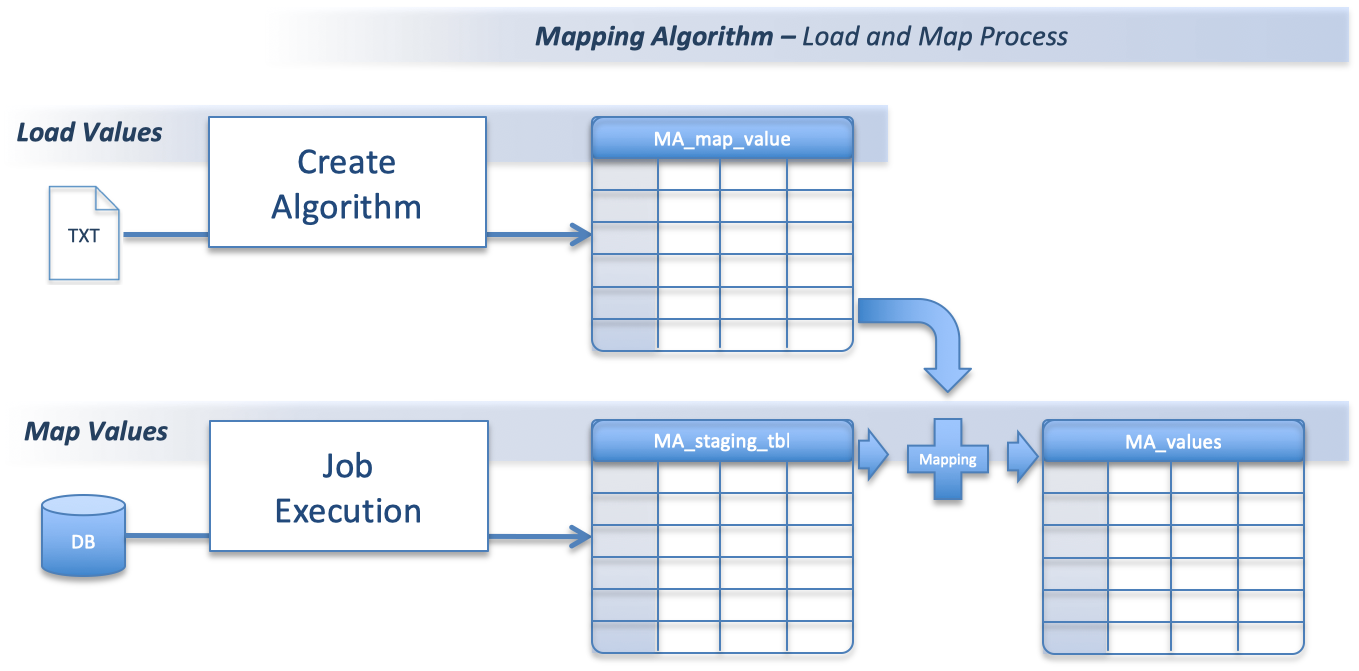
Load Values (into MA_map_value)
This process is started when new values are loaded in to Mapping Algorithm.
- Remove duplicated values from loaded values.
- Remove values already mapped (already in MA_values)
- Uniquely insert values into MA_map_value.
Map Values (into MA_values)
This process is started when the masking job is started and will run before any tables are masked. It is Preparing the Mapping values for the masking job.
- Retrieve all values to be masked from the source column (distinct values).
- Remove values already mapped (already in MA_values).
- Add the values from 1 and 2 (‘distinct and unmapped’) into MA_staging_tbl.
- Count the number of values in MA_map_value and MA_staging_tbl and compare (see below).
- Randomly map (pair) values in MA_staging_tbl with values in MA_map_value.
- Insert new mapped values into MA_values.
- Remove used values from MA_map_value.
Error 'Insufficient mapping values'
If there are not enough unique values left to mask the data in the field - that is not enough values in MA_map_value to map all values in MA_staging_tbl - the job is terminated with an error.
The error message when this happens is:
- 'x' below represent the number of unique values missing.
[JOB_ID_xx_yy] ... WriteToLogTrue.0 - ------------> Linenr 1------------------------------ [JOB_ID_10_48] ... WriteToLogTrue.0 - mapping_algo_id = 1.0 [JOB_ID_10_48] ... WriteToLogTrue.0 - proc_true = Difference is < 0 [JOB_ID_10_48] ... WriteToLogTrue.0 - difference = -x.0 [JOB_ID_10_48] ... WriteToLogTrue.0 - [JOB_ID_10_48] ... WriteToLogTrue.0 - ==================== [JOB_ID_10_48] ... Filter rows.0 - Finished processing (I=0, O=0, R=1, W=1, U=0, E=0) [JOB_ID_10_48] ... Abort.0 - ERROR : Row nr 1 causing abort : [1.0], [-x.0], [Difference is < 0] [JOB_ID_10_48] ... Abort.0 - ERROR : ---------------Insufficient mapping values, please add more mapping values.[MAPPING_ID:1]
Solution
Add additional unique and not already loaded values to the algorithm.
Ignore Characters
Mapping Algorithm has a feature called 'Ignore Characters'.
The feature "Ignore Characters" is applied to the source data to be masked. It is used to ensure that even if the representation of the data is different due to added auxiliary characters, the value is masked to the same value.
Examples
A standard Mapping Algorithm will return these results.
.
+----+----------+----------+---------------------------+ | ID | Orig | Mask | Comment | +----+----------+----------+---------------------------+ | 1 | Smith | Johnson | | | 2 | Smith | Johnson | Leading space is trimmed. | +----+----------+----------+---------------------------+ | 3 | smith | Anderson | MA is case sensitive. | +----+----------+----------+---------------------------+ | 4 | O'Conner | Williams | | | 5 | OConner | Brown | | +----+----------+----------+---------------------------+
Using Ignore Character
Ignore Characters can be used to make data be masked the same even if there are auxiliary characters.
Ignore Characters: -,'
When these two Ignore Characters are used this will be the masked results (Credit Card number added here as an example).
+----+---------------------+------------------+---------------------------+ | ID | Orig | Mask | Comment | +----+---------------------+------------------+---------------------------+ | 4 | O'Conner | Brown | | | 5 | OConner | Brown | | +----+---------------------+------------------+---------------------------+ | 6 | 4000056655665556 | 2223003122003222 | | | 7 | 4000-0566-5566-5556 | 2223003122003222 | Masked to the same value. | +----+---------------------+------------------+---------------------------+
Accented and International Characters
The Mapping Algorithm can be used with International Characters:
Example:
- Both Input and Masked values have accents.
+----+------+------+ | ID | Orig | Mask | +----+------+------+ | 1 | a | á | | 2 | à | å | | 3 | â | ã | | 4 | á | a | | 5 | ã | æ | | 6 | ä | à | | 7 | å | â | +----+------+------+
Memory Requirements
The Mapping algorithm requires memory to load the lookup values when the masking job starts. For large pool sizes, it is required to increase the Min/Max Memory settings in the Job Configuration. The size required depends on the lengths of the data in the lookup and the number of distinct lookup values.
As a ballpark figure, set max to 1 GB + 1 GB per 3 million rows and min 1-2 GB below the max value. It might be required to add more memory to cater for larger data objects and multiple masked columns.
For more information, see Best Practice: Job Configuration on the Masking Engine
Related Articles
The following articles may provide more information or related information to this article:
Knowledge Base:
- Algorithm: Understanding Secure Lookup (SL) Algorithms
- Algorithm: Segmented Mapping
- Best Practice: Job Configuration on the Masking Engine
Documentation: